Accessible Machine Learning & Stock Prices
Completeted March 2023
Technologies Used: Python (Pandas, sklearn, plotly)
I worked with two friends to examine how well accessible machine learning algorithms could predict stock prices. While an algorithm that accurately predicts future market movement is well beyond the scope of a lowly college student, I was curious how far we could get with readily-available models and the computing power of our laptops.
We utilized the algorithms available in the sklearn Python package. We chose Python due to our collective familiarity with using Python for other necessary functions (data collection, cleaning, and visualization).
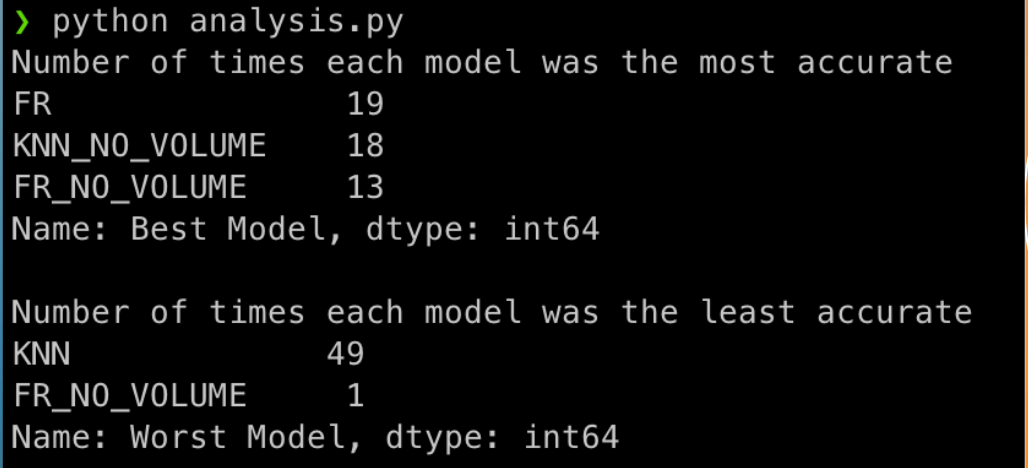
Our project evaluated two algorithms: K-Nearest Neighbors and Random Forest. Both were regressors, as we were using them to predict a numerical value. We also wanted to see which attributes of the data would work best, and ran each algoritm with and without Volume Traded as an input.
To get a sufficiently large sample size, we decided to test each algorithm on the (then) fifty largest companies by market capitalization.
I was responsible for implementing the Machine Learning logic, and did so through the object oriented paradigm. I created a class that took in some price data, ran the algorithms, evaluated their accuracy, and returned RMSE values (error rates). My friends were responsible for creating visualizations and automating the process for all fifty stocks.
We found that the Random Forest algorithm was more accurate overall. Including volume information improved the accuracy of the Random Forest algorithm, but had the opposite effect on the K-Nearest Neighbors algorithm, leading to significantly higher RMSE values.
While the project gave us hands-on machine learning experience, stock price is ultimately driven by external factors. We considered implementing sentiment analysis of News stories to incorporate expectations into our algorithm, but were unable to find an acceptable API at the time.